


What Is A Business Continuity Plan and How Is It Used?
What is a Business Continuity Plan?
What Are The Essential Aspects of A Business Continuity Plan?
Continued Access – A business continuity plan is necessary for accessing required processes and capabilities. It allows businesses to access applications, despite challenges due to their inherent failures. These failures could be due to business processes in the existing IT infrastructure or physical facilities.
Continuous operations – The Business Continuity plan helps organizations perform efficiently even during disruption and planned outages.
Disaster recovery – It establishes an itinerary to recover from a disaster and helps a data center that has become partially or fully inoperable, recover.
What Are The Key Components of A Business Continuity Plan?
01
Strategy
02
Organization
03
Applications and data
04
Processes
05
Technology
06
Facilities
07
People
The business continuity plan is a blueprint to be referred during the crisis with defined strategies to deal with the effects. These key elements play a vital role in creating an effective business continuity plan.
How to Create an Effective Disaster Recovery Plan in 5 Steps?
Identifying Business Continuity Risks
Understanding IT infrastructure is required to identify business continuity risks. The key points to incorporate when determining their scope are –
- Critical information to maintain business operations.
- Critical systems to maintain business operations.
- Critical part of the network to maintain business operations.
- Critical software to maintain business operations.
- Natural disaster risks that impact critical systems, software, and networks.
- Cyber risks that impact networks, software, and systems.
- Critical third-party services required to maintain business operations.
- In-place controls preventing cyber risks to the crucial systems, networks, and software.
- Off-site data center or data backup recovery service.
- In-transit encryption for remote access when the business is interrupted.
- Availability of endpoint encryption in case of business interruption.
- Defined process to implement emergency administrative authorizations.
Disaster Recovery: An Inevitable Subset Of Business Continuity
What Are The Types of Disaster Recovery?

Virtualization Disaster Recovery
Virtualization provides flexibility in disaster recovery. Here servers are virtualized independent from the underlying hardware. Therefore, an organization does not need the same physical servers at the primary site as at its secondary disaster recovery site.

Network Disaster Recovery

Cloud-based Disaster Recovery

Data Center Disaster Recovery
Disaster Recovery as a Service (DRaaS)
Why Should Every Organization Have A Disaster Recovery Plan To Protect Itself?
Perceived and unforeseen threats to operations are always a concern for business owners. In the event of a disaster, the continued operations of an organization depend on the ability of the business to replicate their IT systems and data.
Disaster recovery depicts all the steps involved in planning and adapting to a potential disaster with a plan in place to restore operations while minimizing the long-term negative impact. Good business continuity plans are important to keep a business up and running through interruptions of any kind, including power failures, IT system crashes and natural disasters, and more, thus limiting the short-term negative impact on the company.
Disaster Recovery Plan Vs. Business Continuity Plan
What is the difference between a disaster recovery plan and a contiengency plan?
What is Disaster Recovery?
What is Business Continuity?
A business continuity plan is more of a strategy. It enables operational continuance with minimal downtime and services, or outage.
Achieving a balance between the two strategies is based on the matter of priorities. When your business is mostly online, data security becomes your priority. In the case of a data breach, your business operations may freeze. The competitive intelligence would disappear, making it difficult to make transactions with vendors and customers, and access your inventory information.
The key difference can be identified when the plan is in the implementation stage. Business continuity enables operations to function during the event and aftermath. Whereas, disaster recovery defines how to respond to the event and to return to the normal business phase. While both functionally incorporate a measured response, disaster recovery aims to re-establish the business operations. Though a few areas overlap, they remain distinct in their operation.
The key difference between DR and BC
Requirements To Incorporate Disaster Recovery Planning
After creating a list of risks associated with potential systems, software, and networks, the policies should be considered to enable business recovery from the interruption stage. The key points to be raised as a part of recovery planning are –
- Responsible individuals to require performing the recovery task.
- A timeline for recovery.
- Documentation that proves complete recovery.
- Defined process to implement data recovery.
- Documented chain of command for recovering from the event.
- Complying with a timeline for recovery.
- Measuring compliance with the user authorization policy.
- Measuring the efficacy of incident response.
- Documenting corrective actions.
- Managing the reinstation process aftermath of the event.
How Can AI predict Disasters?
Make sure your disaster recovery plan works when you need it!
The benefit of using Artificial Intelligence in Disaster Recovery
AI can predict potential outcomes
AI contributes to better protection
An AI-enhanced plan can help strategists draft a better plan for disaster recovery. It uses techniques like ‘business impact analysis’ and ‘risk assessment.’
AI automates the disaster recovery process
AI can be used to automate and control various parts of disaster recovery and business continuity plans. It does not only help prevent issues from arising, but also adapts to new data to make it predictive analysis effective.
AI enhances incident response actions
AI can quickly analyze the reason behind the attack and can be programmed to initiate an auto-recovery action.
AI learns from each incident
The more AI is exposed to data to handle downtime and outages, the better they will learn to register the issues of downtime.
Emerging technologies shaping the business continuity and disaster recovery landscape
- Use of virtualization as it makes the restoration easier in case of an incident.
- Backing up data and recovery for mobile users that broadens the disaster recovery landscape.
- Disc-based backup solutions for the massive amount of data being stored on huge data centers.
- Disc-based backup solutions for the massive amount of data being stored on huge data centers.
3 Things that can happen in the absence of disaster recovery plan
Effect on business continuity leading to a major loss.
Extreme financial and reputational loss.
The cost of a data breach creates an additional burden.
3 Steps to a sound disaster recovery plan
3 Tips to build a strong disaster recovery plan
Tip 2
Involve the team in the attack mitigation plan.
Tip 3
Document, implement, and regularly update the recovery plan.
The recent pandemic – COVID-19 calls for a strategic business continuity plan
Business Continuity in the now work from home culture:
Significance Of A Certified and Skilled Cybersecurity Workforce
A certified and skilled cybersecurity workforce always helps strengthen an organization and implement strategic plans and principles to protect its assets. The role of a cybersecurity team majorly focuses on identifying, protecting, detecting, and responding to mitigate the gaps and vulnerabilities in the organization’s network. It is the responsibility of the cybersecurity team along with the disaster management team to implement the following:
A cybersecurity certified team (with a reputed certification like EDRP) to enable communication, collaboration, and co-operation in emergency/disaster management strategies to identify critical assets
- Mitigate the company’s vulnerabilities and threats
- Protect the organization’s data
- Networks and systems
- Perform weekly offsite full system back-ups
- The awareness and training to handle DR and emergency.
- Update the organization’s procedures and policies.
- Monitor internal and external threats
- Vulnerabilities associated with intended and unintended organization’s internal threats due to lack of preparedness towards emergency responses.
- Internal or external threats that cause damage to an organization’s network could go unnoticed until a potential disaster forces an organization to perform restoration of operations.
Disaster recovery IT management and cybersecurity teams work together to train the workforce, create awareness plans, maintain resilience, and enforce operational procedures in the organization.
The question that arises is – how to select the best disaster recovery training from the available choices? One can opt for any business continuity online training. However, there are several points to consider before enrolling in disaster recovery and business continuity programs because the overall objective of the program is to equip us with a skill set that helps us to create a business continuity and disaster recovery plan. The most common assumption while creating such a program is about the audience; only a very few business continuity training is designed in a way that is suitable for beginners, and on the other hand, a few BCP Certifications are designed only for experts.
Primarily, the business continuity plan (BCP) certification/ training must be taken from a well-recognized cybersecurity credentialing body, and secondly, the institution that offers the certifications should have attained globally recognized industry accreditations such as the ISO 17024. An organization must ensure that the course outline of a program they select is aligned with their organizational learning goals.
What To Look For In A Disaster Recovery/Business Continuity Training?
- Business Continuity Management (BCM)
- Business Impact Analysis (BIA)
- Disaster Recovery Planning Process
- System Recovery
- Risk Management
- Recovery Point Objective
- Risk Assessment
- Business Continuity Planning (BCP)
- Data Backup/Recovery Strategies
- Business Continuity Plan (BCP) Review, Maintenance, and Training
- Recovery Time Objective
- Minimum Time of Disruption
Significance Of A Certified and Skilled Cybersecurity Workforce
CBCI by The Business Continuity Institute (BCI)
Business Continuity Management by Certified Information Security
BCLE 2000, BCP 501 & BCP 601 by DRI International, Inc.
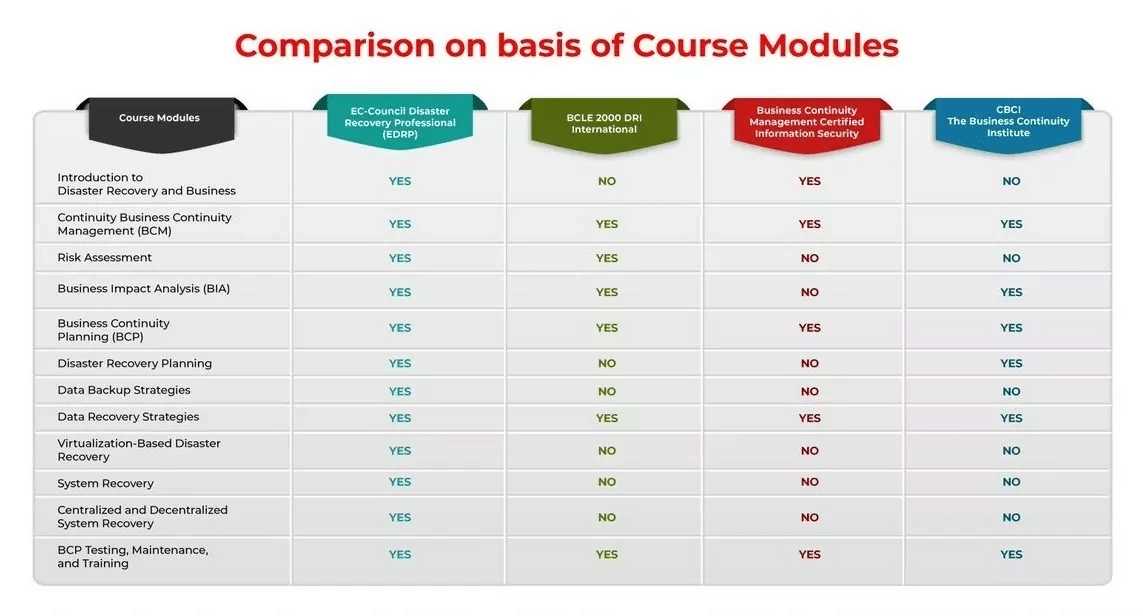
What Is EDRP? What Is Its Significance?
Why EDRP?
Based on the job-task analysis
A program designed by SMEs
Vendor-neutral certification
Hands-on lab
Mapped to NICE Framework and covers various regulatory standards
An additional benefit in the form of whitepapers
Case studies for conceptual learning
Templates to practice
Frequently Asked Questions
- Risk assessment
- Business impact analysis
- Business continuity planning
- Disaster recovery planning process
- Data backup and recovery
- System recovery
- Business continuity plan review and training
EDRP is the best option because in this program, the combines both disaster recovery and business continuity with a major focus on disaster recovery.







